Jerry Chan
•

A few weeks ago, we post-trained NVIDIA's Nemotron 3 Super on Harvey Legal Agent Bench (LAB) benchmark and saw it approach closed model performance on legal work at a fraction of the cost. Since then, NVIDIA released Nemotron 3 Ultra open model, the largest and most capable model in the Nemotron 3 family. While Nemotron 3 Super is a strong mid-size model, Nemotron 3 Ultra is a clear step up: it reasons more deeply, holds far more in working context, and stays fast despite its size. So we put Nemotron 3 Ultra through our LAB evaluation to see how it performs and how far post-training can take it.
Following the launch, we were able to post-train Nemotron 3 Ultra on the Trajectory platform in under 24 hours. Because Trajectory's learning layer is decoupled from any single base model, adopting Nemotron 3 Ultra meant pointing the same harness, data, and recipe we used for Nemotron 3 Super at the new weights, with no new engineering in between.
Nemotron 3 Ultra's performance on LAB
We evaluated Nemotron 3 Ultra on the same held-out LAB tasks and grading we used in our initial experiments. Nemotron 3 Ultra is a more expressive model than Nemotron 3 Super, and that comes through in its post-trainability. Impressively, where Nemotron 3 Super plateaued in performance below the closed frontier, post-training lifts Nemotron 3 Ultra to nearly match today's leading closed models. The headline number is the all-pass rate: the share of held-out tasks where an agent satisfies every rubric criterion, the bar legal work actually sets. Post-trained Nemotron 3 Ultra reaches 5.8%, up from 0% at baseline, placing it between Sonnet 4.6 and Opus 4.6.
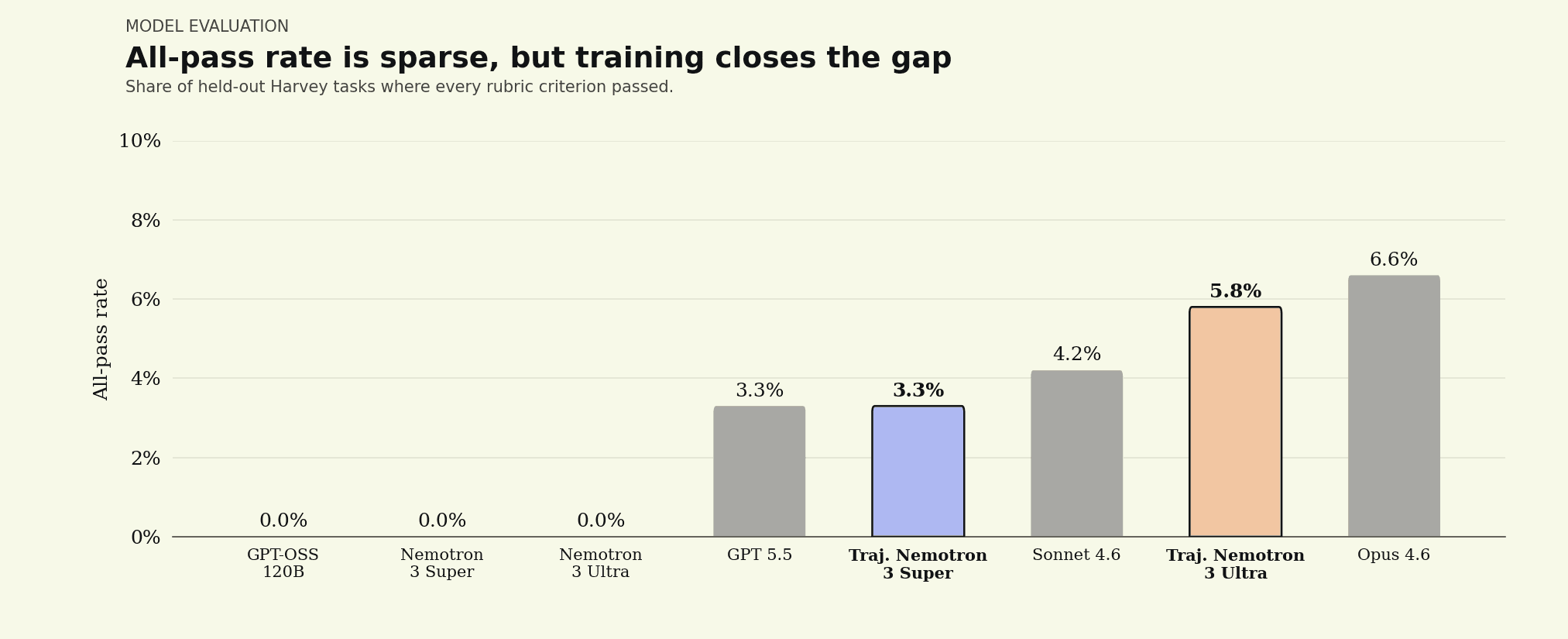
All-pass rate on held-out LAB tasks. Base Nemotron 3 Ultra passes 0% of tasks end-to-end; post-trained, it reaches 5.8%, between Sonnet 4.6 (4.2%) and Opus 4.6 (6.6%), and above post-trained Nemotron 3 Super (3.3%).
Those end-to-end wins rest on broad gains underneath. On the share of individual rubric criteria passed, post-trained Nemotron 3 Ultra lands alongside the leading closed models, which means the all-pass result reflects how completely it handles each task rather than a single hard threshold being cleared.
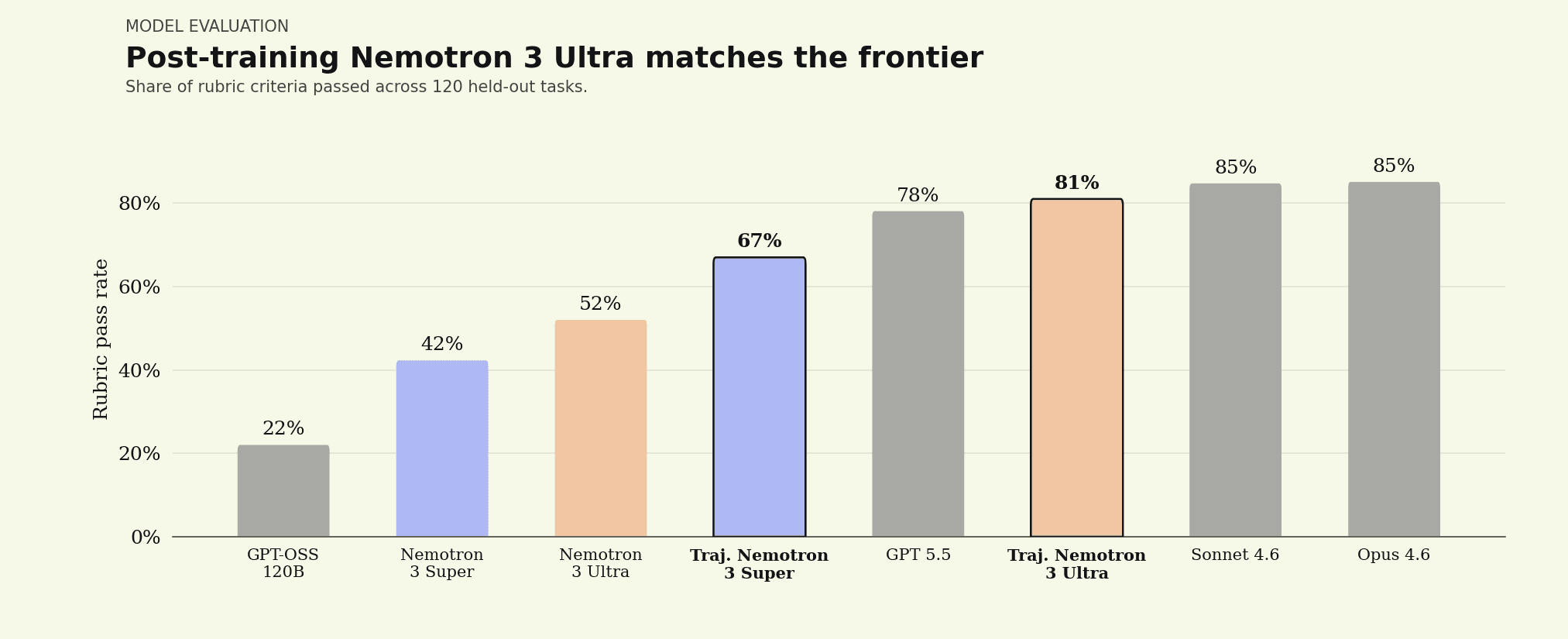
Share of rubric criteria passed. Post-trained Nemotron 3 Ultra reaches 83%, alongside GPT 5.5 (78%), Sonnet 4.6 (85%), and Opus 4.6 (85%), up from 52% for the base model.
In production, a model must not only be accurate, it must also be efficient and affordable to run.Earlier LAB results made the tradeoff clear: frontier closed models are also the most expensive to operate, especially on reasoning-heavy, long-horizon tasks. Post-trained Nemotron 3 Ultra eases that tradeoff, pushing the Pareto frontier of quality and cost. Plotted against price per token, Harvey’s post-trained Nemotron models sit up and to the left of closed frontier models, matching their quality while costing at least 10x cheaper to run.
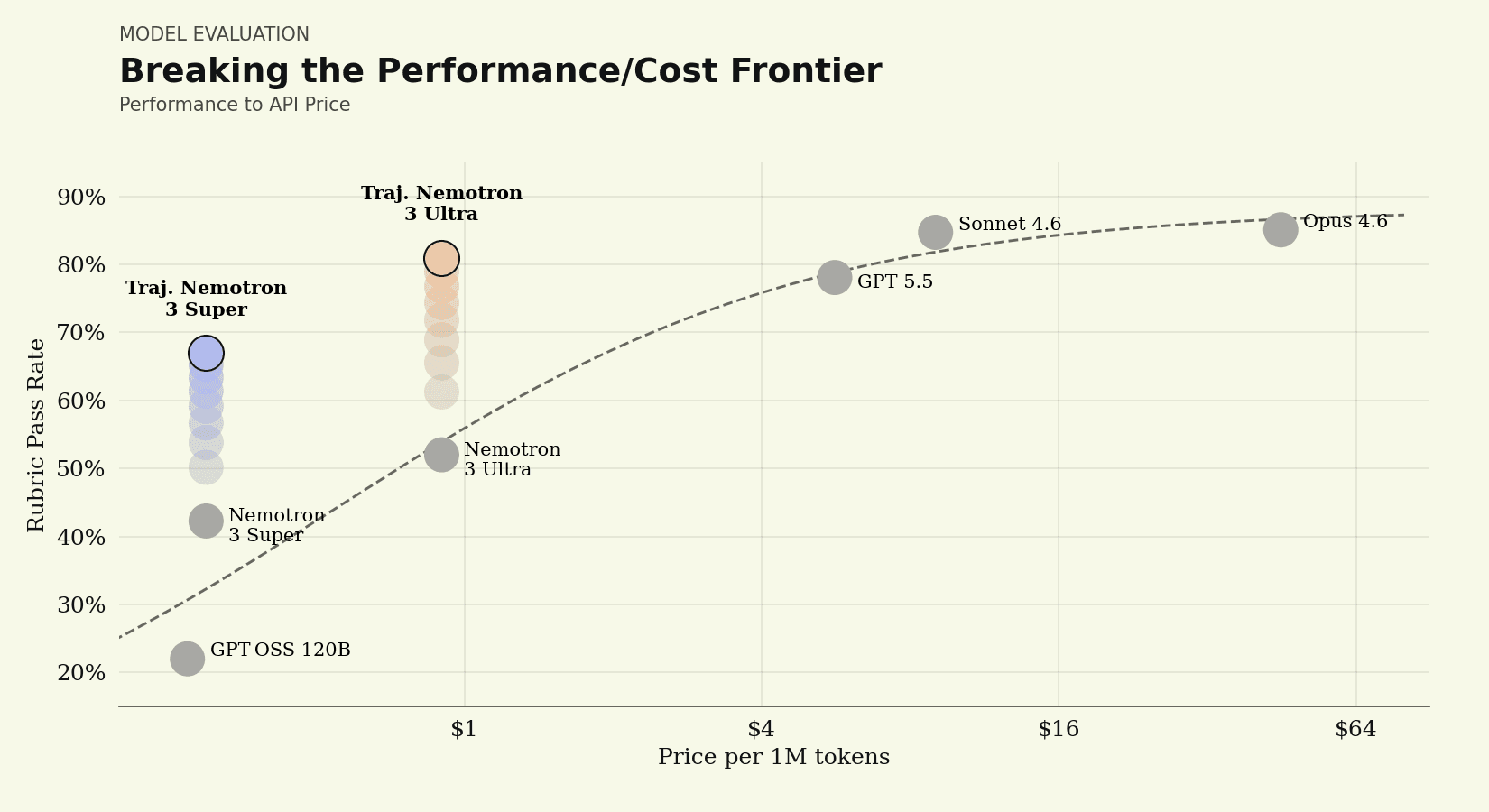
Quality against cost. Post-trained Nemotron 3 Super and Nemotron 3 Ultra clear the price/performance frontier, reaching frontier-level quality at a fraction of the per-token cost of the leading closed models.
The curves below show how a model's per-task rubric scores are distributed across the held-out set, before and after post-training. Before, they spread across the range, with many scores landing between 40-80% criteria pass rate; after, scores mass near the top. The greater the mass shift, the more “trainable” the model is, and the more mass at higher scores, the more reliable the model is at producing useful output for legal tasks. Both models shift, but Nemotron 3 Ultra moves furthest, turning tasks that used to pass around 70% of the time into ones that pass around 95%, the level of reliability legal work demands.
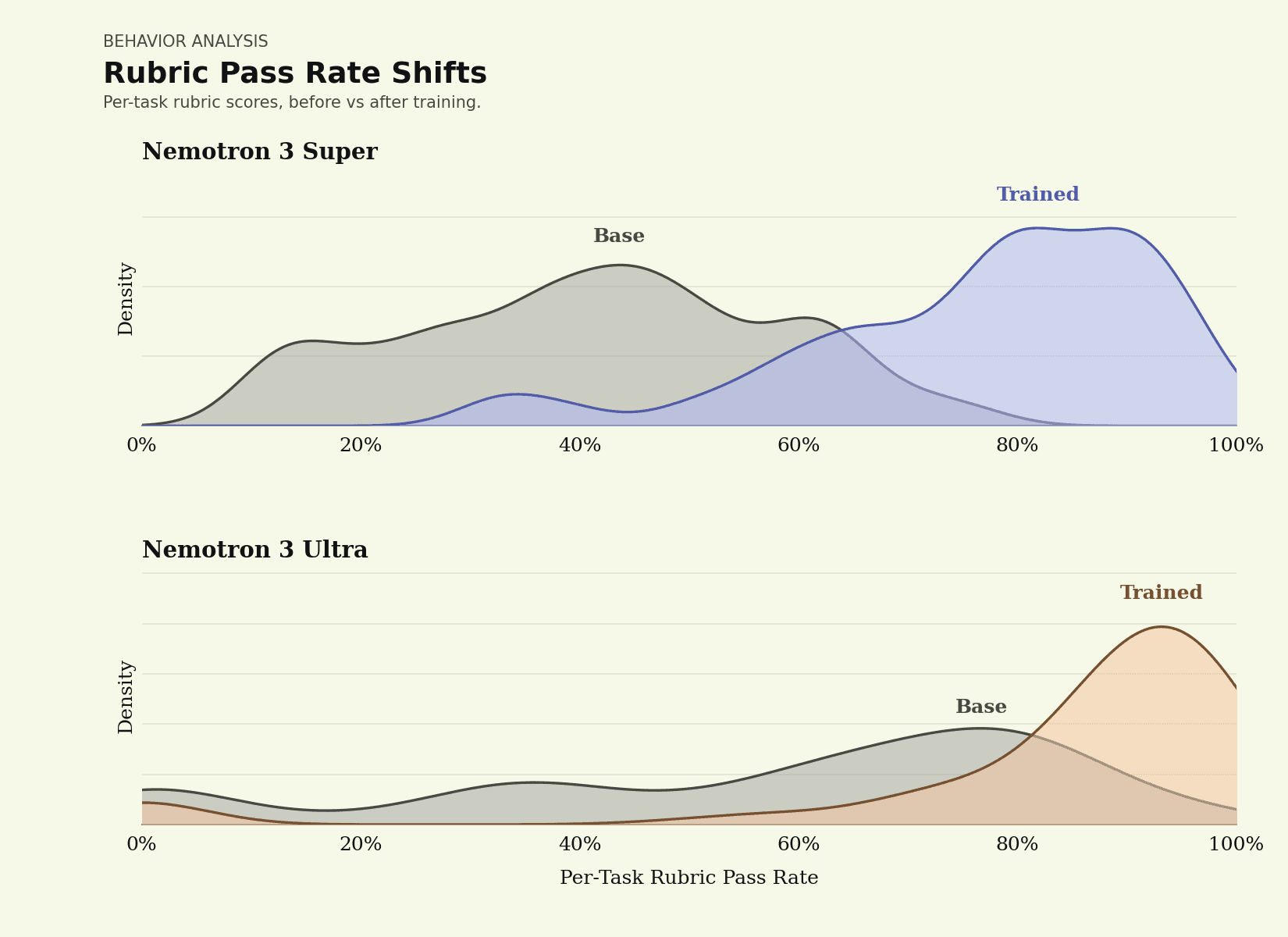
Per-task rubric scores shift toward 80–100% after post-training for both models, and Nemotron 3 Ultra shifts further than Nemotron 3 Super.
In our work on Nemotron 3 Super, we found that post-training builds up the specific capabilities legal work leans on: issue spotting, analysis, citation accuracy, completeness, and the quality of the final recommendation. Nemotron 3 Ultra takes on those same behaviors even more strongly, and the gains land hardest in the practice areas where they matter most.
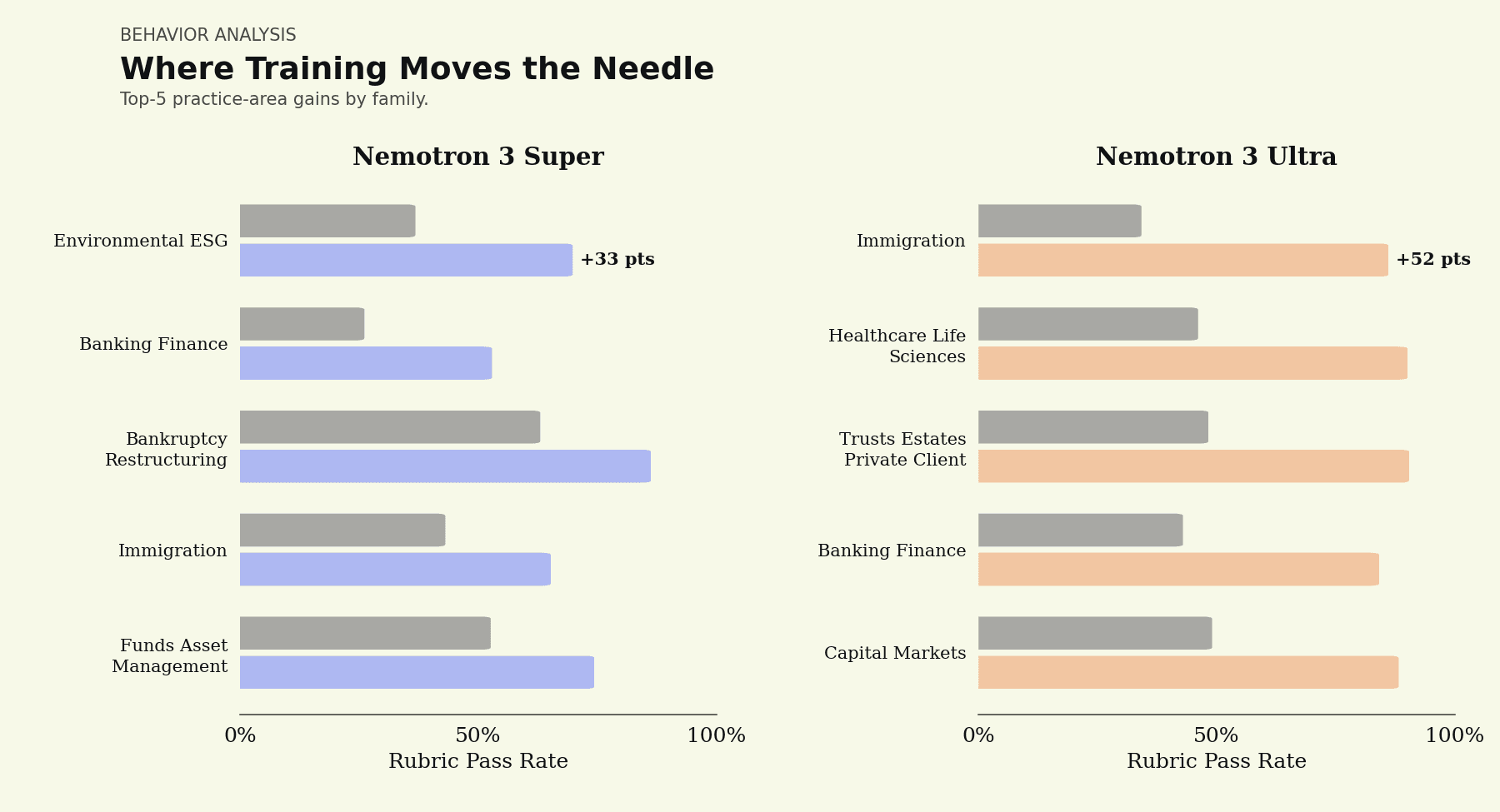
Top-5 capability gains after post-training. Nemotron 3 Super's largest lift is Environmental ESG (+33 pts); Nemotron 3 Ultra's is Immigration (+52 pts).
Taken together, these results place post-trained Nemotron 3 Ultra in the same band as the leading closed models on LAB despite being a fraction of their cost to run. The gains hold across every view: end-to-end completion, rubric coverage, the distribution of per-task reliability, and the specific behaviors legal work depends on. After post-training on legal data, an open-weight model does legal work at frontier quality.
Many models, one pipeline
New open models will keep arriving, each more capable than the last. In that world the advantage doesn't belong to whoever holds the best model on a given day; it belongs to whoever can adopt each new one and keep improving it on their own work. Trajectory is built for that. Because the learning layer is model-agnostic, each new open model can be brought onto the same pipeline and post-trained on a firm's own work, so the models a firm runs keep improving in step with the frontier rather than resetting every time a new one ships.



