Chuck Tang
•

Key Ideas
Continual learning requires models to continuously update from live feedback and production interactions.
At Trajectory, we built a concurrent, multi-LoRA training platform (C-LoRA) for continuously learning workloads.
In our experiments, we achieved a 2.81× end to end experiment-throughput improvement compared to a single-tenant training framework without regressing on any training rewards.
Developed in close collaboration with UC Berkeley Sky Lab and Anyscale, all training code is open-sourced in the NovaSky-AI/SkyRL repository so the broader community can build on top of our work.
1. Introduction
Models today progress in discontinuous jumps in capability. To improve a model, a team must collect data, train, and ship a new version. Not only does this take months, it results in either remarkable or catastrophic behaviors for the downstream user.
At Trajectory, we aim to build the platform for continual learning!
A continual learning system should improve hourly as user interactions enable a model to acquire new capabilities on the fly. Under this paradigm:
A coding agent can learn new engineering patterns as developers correct its work.
A personal assistant can improve planning and prioritization as the user reschedules.
A support agent can resolve hard tickets as operators intervene on difficult cases.
Most training infrastructure still assume a linear lifecycle: allocate GPUs, initialize the model, run a job, spin down, and then repeat.
Continual learning revises this relationship.
When production interactions are taken as training inputs, training becomes part of a live system. The infrastructure that emerges is more like a distributed service, rather than a collection of independent training jobs.
In this post, we analyze the throughput–latency tradeoffs between an always-hot, multi-LoRA training service and a cold-start, single-tenant workflow. The key result is a 2.81× end-to-end experiment-throughput improvement from multi-LoRA training!
2. Status Quo
Today, most modern RL training infrastructure can be reduced to three core primitives:
Sampler. Generates trajectories from the current policy model.
Trainer. Computes gradients and updates the policy model weights from those trajectories.
Parameter synchronization. Updated weights are broadcast back to the inference workers so future rollouts can use the latest policy.
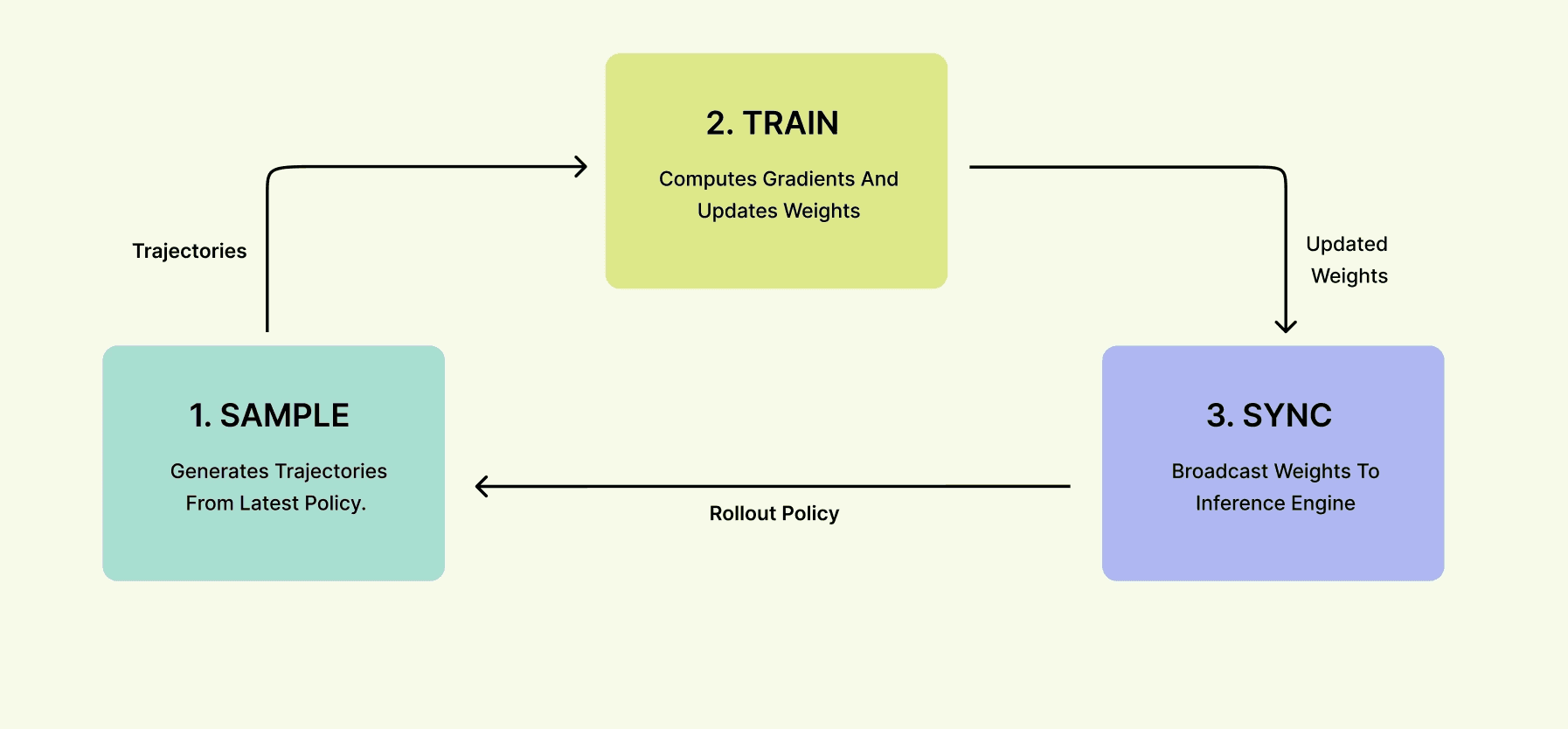
Traditional RL training stacks run this loop as a standalone job where GPU workers are allocated to a single experiment and the loop runs repeatedly.

This training paradigm has four key inefficiencies that our warm, multi-LoRA training stack aims to improve upon.
2.1. Slow, Cold Starts
Every experiment in the serial-job paradigm requires a full restart of the training stack. A restart consists of checkpoint reloads, distributed runtime initialization, and inference engine warmups. For large models, this step alone can exceed 30 minutes per run, throttling iteration speed.
A warm, distributed engine lets us initialize the model once removing the need for per-job spin up times.
2.2. Large, Memory Intensive RL
Frontier models often exceed 100B parameters. Their weights, gradients, and optimizer state must all fit in GPU memory for RL training and sampling, making the hardware cost prohibitively high for many teams to start with. Qwen3.5-397B, for example, can require up to eight H200 nodes to fit into memory.
LoRA training cuts memory usage by an order of magnitude compared to full fine tuning. It freezes the base model so that only a small set of adapter weights, gradients, and optimizer states flow through the model training stack.
2.3. Single-Tenant Training
Traditional RL stacks need to spin up a full set of nodes for every job and can only run a single experiment at a time.
Multi-LoRA training breaks the one-job per set of GPUs paradigm by mapping each experiment to a dedicated LoRA adapter, thereby multiplexing experiment throughput by a factor of N. This lets ML practitioners get early signal across their entire experiment sweep, well before the other N-1 runs finish.
2.4. Low Job Utilization
In synchronous RL training, the trainer stalls while waiting for the inference engine to finish and the inference engine stalls while waiting for the trainer. Async RL is used to address this performance penalty by running the trainer and generator concurrently; however, this introduces off-policy drift and ties together throughput optimizations for training and inference. This problem is compounded in agentic, tool-calling workloads, where the inference engine may sit idle during long tool calls. Furthermore, as the model learns to call tools correctly, the inference workload can shift dynamically, rendering the static load balancing between trainer and generator ineffective.
Multi-LoRA adds a new parallelism knob for improving training utilization by letting you load balance across jobs over time, rather than relying on static, intra-job throughput tuning within a single trainer-generator process group. In our experiments, multi-LoRA training dramatically improved inference throughput for underutilized RL training jobs.
3. Continuous Multi-LoRA Training (C-LoRA)
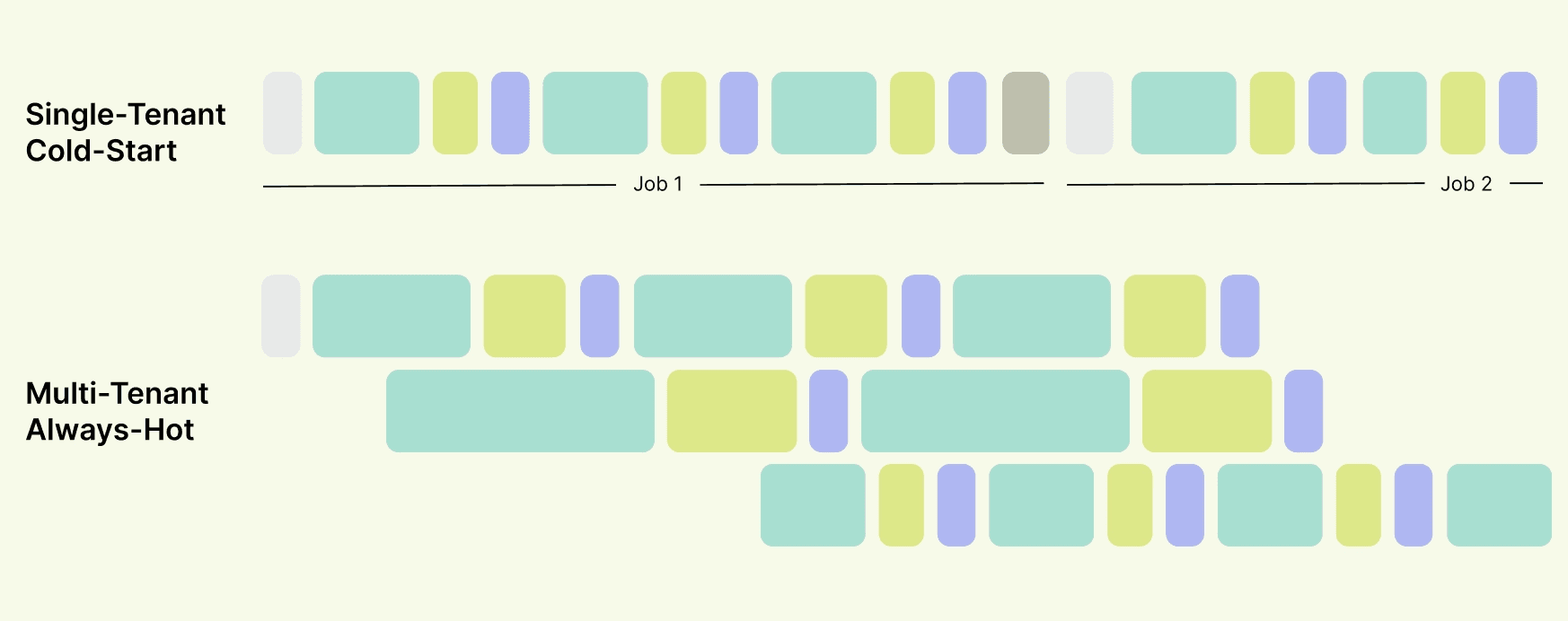
The diagram above showcases how a warm, multi-tenant trainer can run three experiments in parallel faster than a single-tenant baseline running two experiments serially. Together with the Berkeley Sky Lab and AnyScale team, we built this multi-LoRA, always-hot training stack for continual learning workloads at Trajectory. In the section below, we deep dive into the architecture of our platform.
3.1. Architecture

3.1.1 Inference
Inference is where most of the multi-LoRA throughput wins come from for our platform. More specifically, in vLLM, all adapters are hot-loaded in GPU memory so that decode steps can mix tokens from different adapters in the same batch. The key enabler behind this is the SGMV decode kernel which fuses per-adapter matrix-vector work so that multiple LoRAs can share one GPU launch per decode step instead of each LoRA decoding in isolation.
3.1.2 Weight Sync
After each optimization step, updated LoRA weights are loaded in-place into the inference engine. The scheduler does not freeze so other tenants can keep decoding while specific weights are continuously updating. The result behaves more like a continuously running distributed service sending small LoRA weights, than a collection of independent training jobs loading large models.
3.1.3 Training
Training is run across multiple-tenants with one active LoRA adapter that trains on the GPU while the rest of the LoRA adapters sit in pinned CPU memory.
Each tenant's state lives in an AdapterStore, which holds:
LoRA parameters
FP32 master weights
optimizer moments
gradient buffers
The training engine swaps one tenant’s LoRA state from pinned CPU memory onto the GPU, runs a single forward_backward pass on that tenant’s batched inputs, then swaps it back so the next tenant can train. Note: this training path is still single-adapter, so the multi-LoRA concurrency gains we see in inference do not yet apply to training.
3.2 Design Decisions
We scaled the system described above to eight concurrent multi-LoRA runs and achieved a 2.81× higher end-to-end experiment throughput when compared to a single-tenant baseline. Here is a summary of the key dimensions where multi-LoRA RL training outperforms single-tenant.
Dimension | Single-tenant RL | Multi-LoRA RL |
|---|---|---|
Job Startup | Full restart every job: process groups, checkpoint load, inference engine warmup | Adapter attaches to a persistent, warm training engine |
Memory Cost | Weights + gradients + optimizer state for full model on GPU | Large base model weights + small adapter weights, gradients, and optimizer states |
Experiment Throughput | One large model can monopolize the entire cluster | N adapters share one set of nodes; throughput multiplies by N |
GPU Utilization | Imbalanced trainer/generator; off-policy async RL; idle GPUs during tool calls and rollouts | Cross-job load balancing multiplexes rollouts and fills idle capacity |
Scaling Ceiling | Number of nodes | Adapter density on base model |
4. Experiments
4.1 Set Up
We tested multi-LoRA training on a single H200 node with Qwen3-4B-Instruct-2507, running sync RL on GSM8K in an agentic setting. To do so, we reframed GSM8K as a tool use learning task where the model must decide when to invoke custom tools like Calculator and how to structure its response through a Final Answer tool call. This makes the environment substantially richer than the standard one-shot benchmark and provides a stronger training-signal to learn from. The policy initially starts with no knowledge of how to use tools and sits at around 40% accuracy at step 0 in comparison to the 90%+ you'd see on GSM8K. With the right learning algorithm, the model learns how to climb to 90%+ by the end of step 9.
For fair comparison, we swept the baseline runtime configuration values with nine baseline runs for low variance and fast runtimes in the multi-LoRA case and used the following set-up:
Hardware: 1 × H200 node, four inference + four training GPUs
Inference engine: vLLM, tensor_parallel_size=4, max_loras=16, max_cpu_loras=16, max_num_seqs=128
Model: Qwen3-4B-Instruct-2507
Benchmark: GSM8K With Tools
RL config: 10 sync-RL steps
Tools: Calculator, Final Answer
Reward: 1.0 only if the model calls the Final Answer Tool with the correct answer.
Mode: Agentic
Average Steps (Tool Calls): 5
Number of Concurrent, Multi-LoRA Runs: 1, 2, 4, 8
Single LoRA, Baseline Runtime: 2049s
Additionally, we swept all inference and training configs for an optimized single-tenant baseline. This baseline has the same settings as the multi-LoRA run above except:
Inference engine: vLLM, tensor_parallel_size=8, max_loras=1, max_cpu_loras=1 max_num_seqs=1024
Number of Serial, Single-Tenant Runs: 1
Single Tenant, Baseline Runtime: 1905s
4.2 Metrics
There are many metrics to track when designing a cluster-wide training system. A researcher running a batch of experiments wants to know when all the experiment sweeps are done. An infrastructure engineer debugging performance cares about individual step times. An on-call engineer for a hero-run has concerns over when the first experiment will finish.
To capture both experiment throughput and latency, we measure the time it takes to complete M=8 identical training jobs under two settings: (1) a single-tenant baseline ran serially and (2) N=1, 2, 4, 8 multi-LoRA experiments ran in parallel. We track the following metrics below:
Final Experiment Time. When is the last experiment in a batch done?
Mean Experiment Time. What is the average experiment completion time?
First Experiment Time. When is the first experiment in a batch done?
Step Time. How long does the average, single training step take within an experiment?
The first two metrics measures how a sweep, or cluster of experiments are performing (throughput). The second two measure how individual experiments are affected by the multi-LoRA training algorithm (latency).
4.3 Speedups
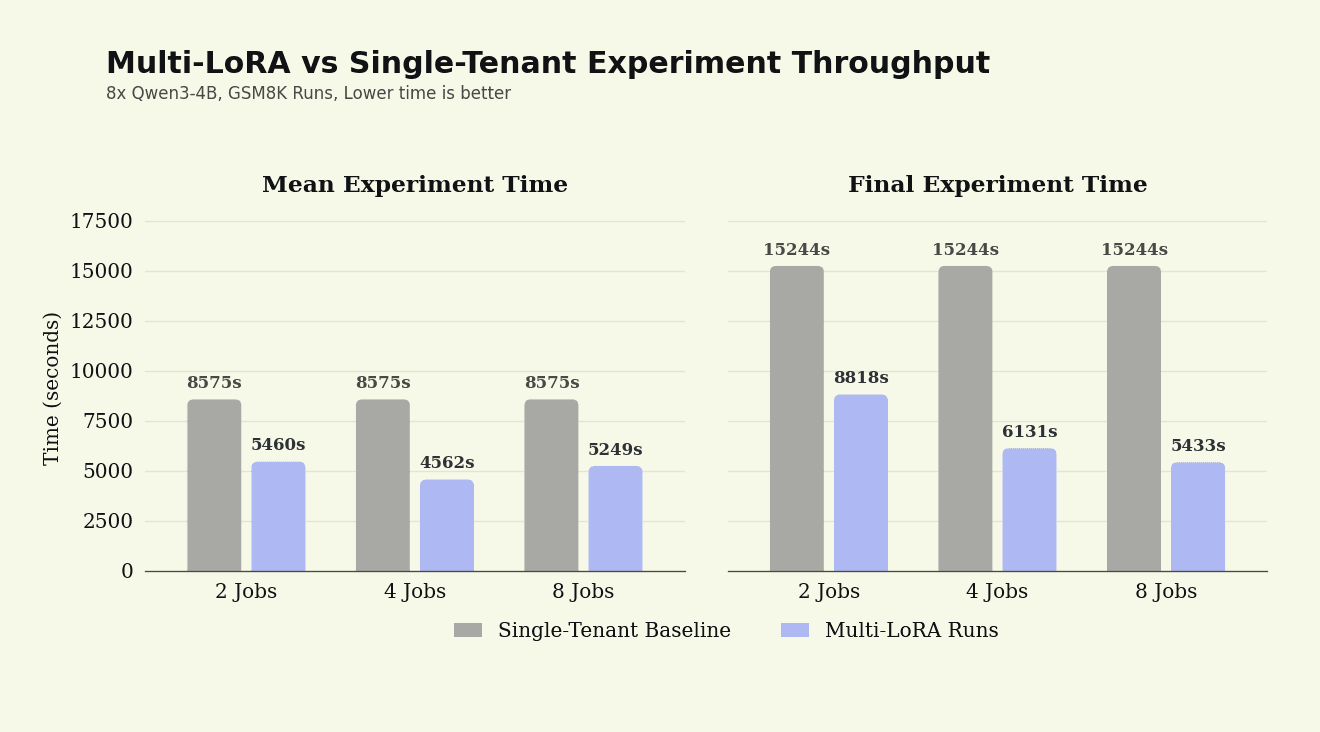
Experiment Settings | Final Experiment Time | Mean Experiment Time | First Experiment Time | Step Time |
|---|---|---|---|---|
Serial, single-tenant, N=1 | 15244 s (1.00x) | 8575 s (1.00x) | 1905 s (1.00x) | 191 s (1.00x) |
Serial, single-LoRA, N=1 | 16395 s (1.08x slower) | 9222 s (1.08x slower) | 2049 s (1.08x slower) | 205 s (1.08x slower) |
Concurrent, Multi-LoRA, N=2 | 8818 s (1.73x faster) | 5460 s (1.57x faster) | 2103 s (1.10x slower) | 215 s (1.13x slower) |
Concurrent, Multi-LoRA, N=4 | 6131 s (2.49x faster) | 4562 s (1.88x faster) | 2992 s (1.57x slower) | 303 s (1.59x slower) |
Concurrent, Multi-LoRA, N=8 | 5433 s (2.81x faster) | 5249 s (1.63x faster) | 3758 s (1.97x slower) | 500 s (2.62x slower) |
Latency and throughput metrics across eight serial, single-tenant experiments versus eight concurrent, multi-LoRA experiments batched at N=1, 2, 4, and 8
We compare eight concurrent, multi-LoRA experiments with eight serial, single-tenant experiments. As shown above, the concurrent batch of eight experiments finished in less wall-clock time than three serial experiments run back-to-back, highlighting a 2.81× speedup in Final Experiment Time!
While the serial baseline, by definition, scales linearly in Final Experiment Time, the multi-LoRA runs scale sub-linearly, with the gap widening from N=2 to N=4 to N=8 jobs. This makes sense; in the serial baseline, GPUs are underutilized during tool calls and synchronous training while the rollout engine waits for external results. Multi-LoRA parallelizes across experiments to fill these underutilized slots.
We also observe that the Mean Experiment Time improves as concurrency increases, peaking at N=4 with a 1.88× speedup over the average serial experiment completion time. This means that both your experiment sweep and your average experiment will finish faster in the Multi-LoRA setting versus the single-tenant setting!
4.4 Tradeoffs
Multi-LoRA training improves overall experiment throughput but it increases per-step latency. As N, the number of experiments grows, two metrics degrade: First Experiment Time (how long the fastest experiment finishes) and Step Time (how long each step takes) relative to the single baseline.
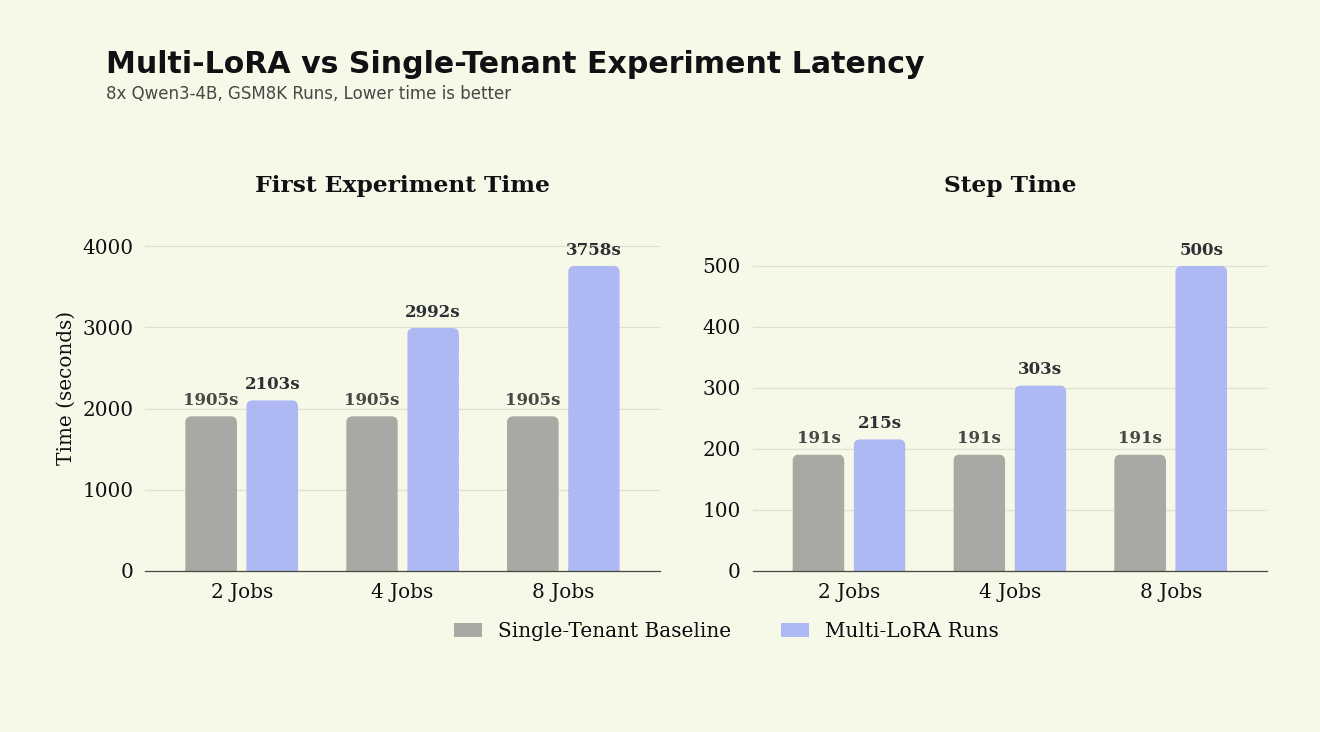
Step time grows sub-linearly with N as inference load increases, a sign that the engine is becoming more saturated which is generally good! The tradeoff is that individual experiments wait longer. Specifically, at N=8, the first serial, single-tenant experiment finishes 1.97x faster than the concurrent, multi-LoRA run.
4.5 Stepwise Runtime
Digging a bit deeper into the stepwise runtimes, at N=8, Multi-LoRA training runs up to 8x the experiment load while the mean step time rises from 191s to 500s, only 2.62x slower than the single-tenant baseline. Most of this increase comes from rollout time with rollout growing from 162s at N=1 to 401 s at N=8, a 2.47x increase and roughly 77% of the total step-time increase. This highlights multi-LoRA inference as a key improvement area for the future. At N=2, the inference engine handles double the load with only a 15% rollout-time increase, which is the ideal Multi-LoRA use case filling idle serving capacity without materially slowing down each job.

On the trainer side, training could in theory become up to Nx slower because each LoRA adapter still requires its own training update. In practice we observe less than Nx scaling with training time being 2.22x higher at N=4 and 3.81x higher at N=8, showcasing that sync RL is overlapping work efficiently. Below we see a gantt chart of eight concurrent multi-LoRA runs running in parallel in comparison to its serial baseline. Once again, we accentuate that all eight of the multi-LoRA runs finish in parallel before three of the single-tenant baselines finish running.

4.6 Accuracy Checks
To validate multi-LoRA training improved in experiment throughput without regressing in accuracy, we checked that all multi-LoRA runs match the end serial baseline accuracy. In the graph below, we see that the concurrent training run reward_accuracy tracks the serial baseline within ±1σ across the last 4 steps of training. More importantly, all concurrent trainers reach reward_accuracy > 90% by step 9 at every concurrency level (N=1,2,4,8).

5. Getting Started
One of the goals of this work is to make multi-LoRA RL training infrastructure accessible outside a small number of large internal teams. Here is a simple way to get started on a 8× H100/H200 setup using open-source libraries from SkyRL and the Tinker cookbook.
5.1 Requirements
A node with 8 visible NVIDIA H100/H200 GPUs and CUDA 12.8+ driver stack.
≥200 GB free disk for uv / HF / model / checkpoint caches
Container image:
novaskyai/skyrl-train-ray-2.51.1-py3.12-cu12.8.
5.2 Launch multi-LoRA endpoint
Inside the container as root run the following script:
Run a quick health check to ensure your SkyRL endpoint is up:
The end-to-end first-time start (download wheels + build TE + Megatron worker bring-up) was ~22 min on our test node. Subsequent restarts on the same uv-cache are ~2 min.
5.3 Launch 4 concurrent experiments
Now that your endpoint is up, let's launch the 4 concurrent GSM8k experiments!
You should see the lines below replicated 4x per step, indicating that you are now training on 4 multi-LoRA experiments! Double check your wandb plots to confirm.
5.4 Throughput Speedups
In this demo, increasing the SkyRL engine from 1 LoRA to 4 LoRAs adds only ~16% per-step latency while delivering ~3.25× more LoRA-steps per wall time!
Concurrency | Step Time | Total LoRA-steps | First Experiment Time | Finish Experiment Time |
|---|---|---|---|---|
N=1 | 25.5 s | 10 | 4.25 min | 4.25 min |
N=4 | 29.6 s | 40 | 4.55 min | 5.20 min |
6. Future Work
We see the system described above as an early design rather than a finished architecture. There are several directions we are excited about exploring in the near future:
Higher adapter concurrency: we have scaled to eight concurrent LoRA experiments. Next, can we push the number of LoRA adapters even higher?
Larger models: so far, we have tested primarily on mid-sized models like Qwen3-4B and Nemotron-30B. Next, can we extend this framework to frontier-scale models with trillions of parameters?
Training-side multiplexing: today, most of the throughput gain comes from inference, while training remains serialized across tenants. Next, can we bring vLLM-style multiplexing into training so that training optimizations can run concurrently as well?
7. Closing Thoughts
At Trajectory, we are building the platform for continual learning.
We expect models to improve quickly through tight train-deploy loops that seamlessly incorporate feedback, evaluations, and new behaviors. As that happens, the boundary between training and production systems will begin to fade.
Our goal with this work is to make that shift more accessible through open-source, concurrent, always-hot training infrastructure.
If you are excited about building such systems, we’d love to hear from you at hello@trajectory.ai.
8. Acknowledgments
We’d like to thank the SkyRL team: Eric Tang, Charlie Ruan, Philipp Moritz, and Sumanth Hegde for their work in building out core components of the Multi-LoRA training stack in SkyRL
We’d like to thank the Google Cloud team for their partnership and guidance in shaping the Kubernetes orchestration of our training platform.
We’d like to thank Dian Ang Yap, Jerry Chan, Ronak Malde, Michael Elabd, Irene Han, Hersh Godse, Arjun Karanam, Neil Kale, and Albert Li for their contributions to the technical portions of this blog post.
9. Additional Experiments
We ran the same multi-LoRA, concurrent experiments and serial, single-tenant baselines on the τ-bench retail task. This benchmark contains custom tools, is long-context, and uses the MoE model NVIDIA-Nemotron-3-Nano-30B-A3B-BF16.
At N=2, Multi-LoRA finishes 10 steps of training 1.28x faster than running the jobs serially. The tradeoff remains that each tenant’s step time increased by 1.57x because serving now has higher inference workloads and training processes each multi-LoRA batch one by one.
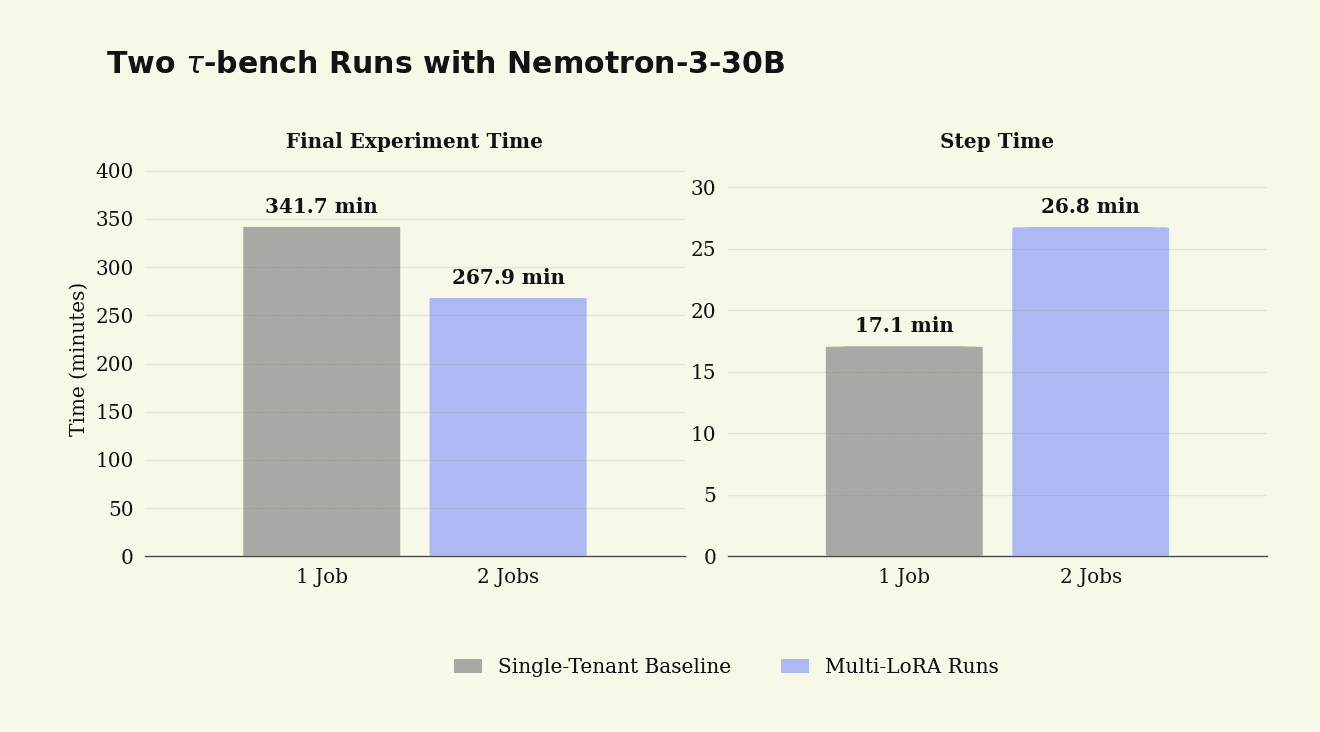
On τ-bench retail with Nemotron 30B MoE, Multi-LoRA reduces total wall time for the two-job batch while regressing on average step time.
These results mirror what we saw on smaller models (Qwen3-4B) and simpler benchmarks (GSM8K) giving us the confidence to scale this approach to larger models and more demanding workloads!
10. Citation
Please cite this work as:
Or use the BibTeX citation



